

一、半同步复制(扩展)
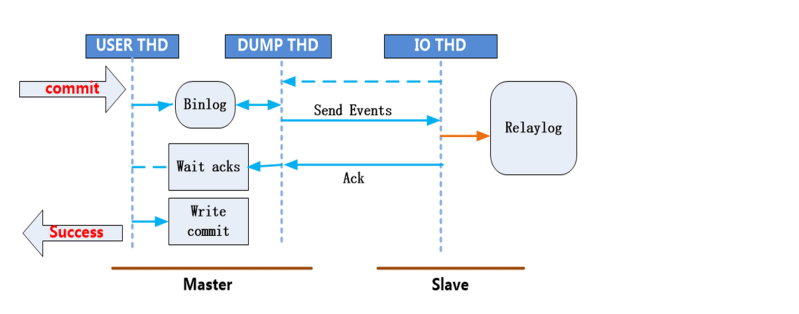
所谓的半同步复制就是master每commit一个事务(简单来说就是做一个改变数据的操作),要确保slave接受完主服务器发送的binlog日志文件==并写入到自己的中继日志relay log里==,然后会给master信号,告诉对方已经接收完毕,这样master才能把事物成功==commit==。这样就保证了master-slave的==数据绝对的一致==(但是以牺牲==master的性能为代价==).但等待时间也是可以调整的。
1、准备M-S复制架构
自己准备完成
2、半同步复制配置步骤
第一步:安装插件
插件存放目录:``$basedir/lib/plugin/`
- master上安装插件
mysql> install plugin rpl_semi_sync_master soname 'semisync_master.so';
Query OK, 0 rows affected (0.00 sec)
查看是否安装成功
mysql> show global variables like 'rpl_semi_sync%';
+------------------------------------+-------+
| Variable_name | Value |
+------------------------------------+-------+
| rpl_semi_sync_master_enabled | OFF |
是否启用master的半同步复制
| rpl_semi_sync_master_timeout | 10000 |
默认主等待从返回信息的超时间时间,10秒。动态可调
| rpl_semi_sync_master_trace_level | 32 |
用于开启半同步复制模式时的调试级别,默认是32
| rpl_semi_sync_master_wait_no_slave | ON |
是否允许每个事物的提交都要等待slave的信号.on为每一个事物都等待,off则表示slave追赶上后,也不会开启半同步模式,需要手动开启
+------------------------------------+-------+
- slave上安装插件
mysql> install plugin rpl_semi_sync_slave soname 'semisync_slave.so';
mysql> show global variables like 'rpl_semi_sync%';
+---------------------------------+-------+
| Variable_name | Value |
+---------------------------------+-------+
| rpl_semi_sync_slave_enabled | OFF | slave是否启用半同步复制
| rpl_semi_sync_slave_trace_level | 32 |
+---------------------------------+-------+
第二步:激活半同步复制
- master上
mysql> set global rpl_semi_sync_master_enabled =on;
mmysql> show global status like 'rpl_semi_sync%';
+--------------------------------------------+-------+
| Variable_name | Value |
+--------------------------------------------+-------+
| Rpl_semi_sync_master_clients | 1 |
有一个从服务器启用半同步复制
| Rpl_semi_sync_master_net_avg_wait_time | 0 |
master等待slave回复的平均等待时间。单位毫秒
| Rpl_semi_sync_master_net_wait_time | 0 |
master总的等待时间。单位毫秒
| Rpl_semi_sync_master_net_waits | 0 |
master等待slave回复的总的等待次数
| Rpl_semi_sync_master_no_times | 0 |
master关闭半同步复制的次数
| Rpl_semi_sync_master_no_tx | 0 |
表示从服务器确认的不成功提交的数量
| Rpl_semi_sync_master_status | ON |
标记master现在是否是半同步复制状态
| Rpl_semi_sync_master_timefunc_failures | 0 |
master调用时间(如gettimeofday())失败的次数
| Rpl_semi_sync_master_tx_avg_wait_time | 0 |
master花在每个事务上的平均等待时间
| Rpl_semi_sync_master_tx_wait_time | 0 |
master花在事物上总的等待时间
| Rpl_semi_sync_master_tx_waits | 0 |
master事物等待次数
| Rpl_semi_sync_master_wait_pos_backtraverse | 0 |
后来的先到了,而先来的还没有到的次数
| Rpl_semi_sync_master_wait_sessions | 0 |
当前有多少个session因为slave回复而造成等待
| Rpl_semi_sync_master_yes_tx | 0 |
表示从服务器确认的成功提交数量
+--------------------------------------------+-------+
- slave上
mysql> set global rpl_semi_sync_slave_enabled=on;
mysql> show global status like 'rpl_semi_sync%';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Rpl_semi_sync_slave_status | ON |
+----------------------------+-------+
第三步:重启slave的IO线程
mysql> stop slave IO_THREAD;
mysql> start slave IO_THREAD;
第四步:测试验证
==原理:==
当slave从库的IO_Thread 线程将binlog日志接受完毕后,要给master一个确认,如果超过10s未收到slave的接收确认信号,那么就会自动转换为传统的异步复制模式。
- master插入一条记录,查看slave是否有成功返回(在master上操作)
mysql> insert into a values (3);
Query OK, 1 row affected (0.01 sec)
mysql> show global status like 'rpl_semi_sync%_yes_tx';
+-----------------------------+-------+
| Variable_name | Value |
+-----------------------------+-------+
| Rpl_semi_sync_master_yes_tx | 1 |
表示这次事物成功从slave返回一次确认信号
+-----------------------------+-------+
-
slave上模拟故障查看返回时间
当slave挂掉后,master这边更改操作
# service stop mysql
或者直接停止slave的IO_thread线程
mysql> stop slave io_thread;
mysql> insert into a values (4);
Query OK, 1 row affected (10.00 sec)
这次插入一个值需要等待10秒(默认的等待时间)
mysql> insert into a values (5);
Query OK, 1 row affected (0.01 sec)
现在自动转成了原来的异步模式
- 再次启动slave,查看同步模式
mysql> show global status like 'rpl_semi_sync%';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Rpl_semi_sync_slave_status | OFF |
+----------------------------+-------+
如需要再次半同步复制,则按照以上步骤重新开启就可以
mysql> set global rpl_semi_sync_slave_enabled=on;
mysql> stop slave IO_THREAD;
mysql> start slave IO_THREAD;
或者可以将该参数写入到配置文件中:
master:rpl_semi_sync_master_enabled=1
slave:rpl_semi_sync_slave_enabled=1
-
测试结果
-
master需要等到slave确认后才能提交,如果等不到确认消息,master等待10s种后自动变成异步同步;slave启起来后,master上改变的数据还是会自动复制过来,数据又回到一致。
-
等待时间可以在master上动态调整,如下
mysql> set global rpl_semi_sync_master_timeout=3600000;
mysql> show global variables like 'rpl_semi_sync%';
+------------------------------------+---------+
| Variable_name | Value |
+------------------------------------+---------+
| rpl_semi_sync_master_enabled | ON |
| rpl_semi_sync_master_timeout | 3600000 |
| rpl_semi_sync_master_trace_level | 32 |
| rpl_semi_sync_master_wait_no_slave | ON |
+------------------------------------+---------+
二、MHA(数据库高可用解决方案)
任务背景
随着业务功能的逐步完善,现有MySQL数据库架构虽然可以保障数据的相对可靠性,但是不能够完全保障==服务的可用性。==当我们的主库挂掉后,mysql服务不能立马切换到从服务器。所以,需要在现有架构的基础上==扩展和升级,==进而在保障数据的可靠性的同时能够保障服务的可用性。
任务要求
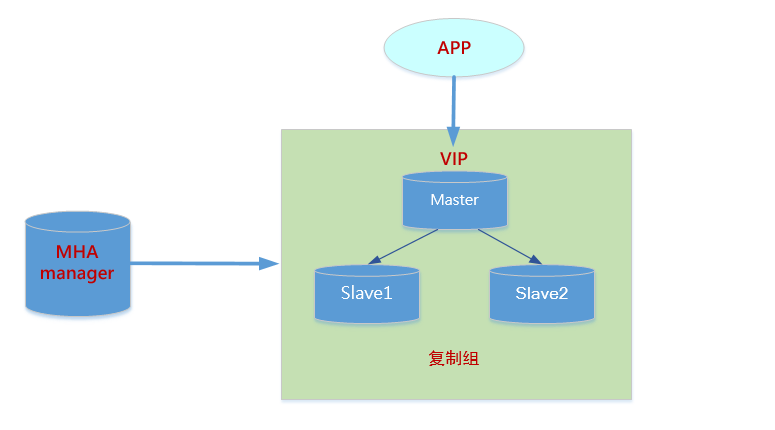
- 使用三台服务器搭建mysql的复制组(1主两从)
- 使用==MHA==管理复制组,当master挂掉后,会立马提升一台slave作为新的master
任务拆解
- 搭建MySQL的复制组(M-S1-S1,并联架构)
- 安装MHA相关软件来管理复制组
理论储备
1、MHA简介
MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebook公司)开发,是一套优秀的作为MySQL高可用性环境下==故障切换和主从提升==的高可用软件。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在==较大程度==上保证数据的一致性,以达到真正意义上的高可用。
2、MHA工作原理
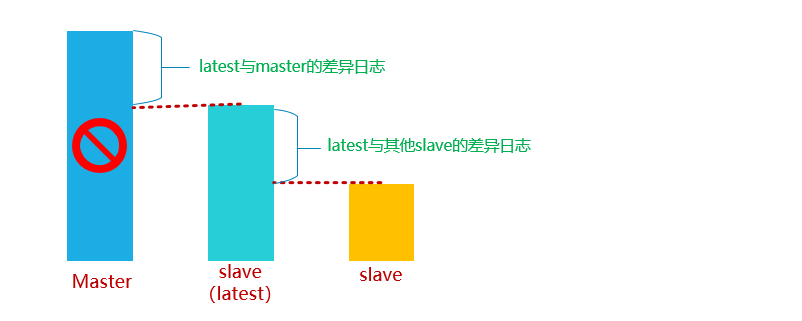
① 当master出现故障时,通过对比slave之间I/O线程读取master上binlog的位置,选取最接近的slave做为最新的slave(latest slave)。
② 其它slave通过与latest slave对比生成差异中继日志,并应用。
③ 在latest slave上应用从master保存的binlog,同时将latest slave提升为master。
④ 最后在其它slave上应用相应的差异中继日志并开始从新的master开始复制.
3、MHA组件
==MHA Manager==(管理节点) 和 ==MHA Node==(数据节点)
- MHA Manager可以单独部署在一台独立的机器上管理多个==master-slave集群==,也可以部署在一台slave节点上。
- MHA Node运行在==每台MySQL服务器==上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。
4、组件介绍
- MHA Manager
运行一些工具,比如masterha_manager工具实现自动监控MySQL Master和实现master故障切换,其它工具手动实现master故障切换、在线mater转移、连接检查等等。一个Manager可以管理多 个master-slave集群
- MHA Node
部署在所有运行MySQL的服务器上,无论是master还是slave。主要有三个作用:
1)保存二进制日志
如果能够访问故障master,会拷贝master的二进制日志
2)应用差异中继日志
从拥有最新数据的slave上生成差异中继日志,然后应用差异日志。
3)清除中继日志
在不停止SQL线程的情况下删除中继日志
5、相关工具
Manager工具:
- ==masterha_check_ssh : 检查MHA的SSH配置==
- ==masterha_check_repl : 检查MySQL复制==
- ==masterha_manager : 启动MHA==
- ==masterha_check_status : 检测当前MHA运行状态==
- masterha_master_monitor : 监测master是否宕机
- masterha_master_switch : 控制故障转移(自动或手动)
- masterha_conf_host : 添加或删除配置的server信息
Node工具
- save_binary_logs : 保存和复制master的二进制日志。
- apply_diff_relay_logs : 识别差异的中继日志事件并应用于其它slave。
- filter_mysqlbinlog : 去除不必要的ROLLBACK事件(MHA已不再使用这个工具)。
- purge_relay_logs : 清除中继日志(不会阻塞SQL线程)。
==注意:Node这些工具通常由MHA Manager的脚本触发,无需人手操作==。
三、MHA部署
1. 部署规划
| 角色 | IP | 主机名 | server-id | 功能 | 备注 |
|---|---|---|---|---|---|
| MHA-Manager | 10.1.1.40 | mgr.itcast.cn | — | 管理节点 | |
| MHA-Node(Master) | 10.1.1.10 | master.itcast.cn | 10 | 数据节点 | 写 |
| MHA-Node(Slave1) | 10.1.1.20 | slave1.itcast.cn | 20 | 数据节点 | 读 |
| MHA-Node(Slave2) | 10.1.1.30 | slave2.itcast.cn | 30 | 数据节点 | 读 |
2. 环境准备
| 系统版本 | MySQL版本 | MHA版本 |
|---|---|---|
| CentOS 7.5 | MySQL-5.6.35 | mha4mysql-manager-0.57 mha4mysql-node-0.57 |
3. 系统环境初始化
3.1 修改主机名和hosts
# hostnamectl set-hostname master.itcast.cn
# hostnamectl set-hostname slave1.itcast.cn
# hostnamectl set-hostname slave2.itcast.cn
# hostnamectl set-hostname mgr.itcast.cn
# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.1.1.10 master.itcast.cn master
10.1.1.20 slave1.itcast.cn slave1
10.1.1.30 slave2.itcast.cn slave2
10.1.1.40 mgr.itcast.cn mgr
3.2 关闭防火墙和selinux
# systemctl stop firewalld
# systemctl disable firewalld
# setenforce 0
# sed -i '/SELINUX=enforcing/cSELINUX=disabled' /etc/selinux/config
3.3 关闭NetworkManager服务
# systemctl stop NetworkManager
# systemctl disable NetworkManager
3.4 配置yum源
说明:分别配置 aliyun、epel 和本地源;
# rpm -ivh /soft/mha/epel-release-latest-7.noarch.rpm
[root@db01 yum.repos.d]# cat server.repo
[local]
name=local yum
baseurl=file:///mnt
enabled=1
gpgcheck=0
[aliyun]
name=aliyun yum
baseurl=http://mirrors.aliyun.com/centos/7/os/x86_64/
enabled=1
gpgcheck=0
注意:如果没有网络可以使用本地仓库,提前下载好包
[root@master data]# cd /etc/yum.repos.d/
[root@master yum.repos.d]# cat server.repo
[local]
name=local yum
baseurl=file:///mnt
enabled=1
gpgcheck=0
[mha]
name=mha soft
baseurl=file:///soft/mha/mha-yum
enabled=1
gpgcheck=0
说明:
1)每台服务器都需要配置该文件
2)每台服务器都需要/soft/mha/mha-yum目录来保存相应的软件包
3.5 安装依赖包
注意:所有服务器均需要安装
yum -y install perl-DBD-MySQL \
perl-Config-Tiny \
perl-Time-HiRes \
perl-Mail-Sender \
perl-Mail-Sendmail \
perl-MIME-Base32 \
perl-MIME-Charset \
perl-MIME-EncWords \
perl-Params-Classify \
perl-Params-Validate.x86_64 \
perl-Log-Dispatch \
perl-Parallel-ForkManager \
net-tools
4. 部署MySQL复制环境
4.1 MySQL部署规划
| 安装目录 | 数据库目录 | 配置文件 | 套接字文件 | 端口 |
|---|---|---|---|---|
| /usr/local/mysql | /usr/local/mysql/data | /etc/my.cnf | /usr/local/mysql/mysql.sock | 3306 |
4.2 搭建主从复制
1. 创建配置文件
[root@master ~]# cat /etc/my.cnf
[mysqld]
basedir=/usr/local/mysql
datadir=/usr/local/mysql/data
port=3306
socket=/usr/local/mysql/mysql.sock
log-error=/usr/local/mysql/data/master.err
character_set_server=utf8mb4
log-bin=/usr/local/mysql/data/binlog
server-id=10
gtid-mode=on
log-slave-updates=1
enforce-gtid-consistency
[client]
socket=/usr/local/mysql/mysql.sock
[root@slave1 ~]# cat /etc/my.cnf
[mysqld]
basedir=/usr/local/mysql
datadir=/usr/local/mysql/data
socket=/usr/local/mysql/mysql.sock
log-error=/usr/local/mysql/data/slave1.err
log-bin=/usr/local/mysql/data/mybinlog
character_set_server=utf8mb4
server-id=20
relay-log=/usr/local/mysql/data/relaylog
gtid-mode=on
log-slave-updates=1
enforce-gtid-consistency
skip-slave-start
[client]
socket=/usr/local/mysql/mysql.sock
[root@slave2 ~]# cat /etc/my.cnf
[mysqld]
basedir=/usr/local/mysql
datadir=/usr/local/mysql/data
socket=/usr/local/mysql/mysql.sock
log-error=/usr/local/mysql/data/slave2.err
log-bin=/usr/local/mysql/data/mybinlog
character_set_server=utf8mb4
server-id=30
relay-log=/usr/local/mysql/data/relaylog
gtid-mode=on
log-slave-updates=1
enforce-gtid-consistency
skip-slave-start
[client]
socket=/usr/local/mysql/mysql.sock
2. 将master原有数据分别同步到slave1和slave2上
1)slave1、slave2、mgr上分别创建mysql用户
# useradd mysql
2)master同步数据到所有slave上
[root@master ~]# rsync -av /usr/local/mysql 10.1.1.20:/usr/local/
[root@master ~]# rsync -av /usr/local/mysql 10.1.1.30:/usr/local/
3) 删除三台服务器上的auto.cnf文件
[root@master data]# rm -f auto.cnf
[root@slave1 data]# rm -f auto.cnf
[root@slave2 data]# rm -f auto.cnf
3. 启动三台数据库服务器
[root@master data]# service mysql start
Starting MySQL.Logging to '/usr/local/mysql/data/master.itcast.cn.err'.
.. SUCCESS!
[root@slave1 data]# service mysql start
Starting MySQL.Logging to '/usr/local/mysql/data/slave1.itcast.cn.err'.
. SUCCESS!
[root@slave2 data]# service mysql start
Starting MySQL.Logging to '/usr/local/mysql/data/slave2.itcast.cn.err'.
.. SUCCESS!
4. 在master上分别创建复制和mha用户
mysql> grant replication slave, replication client on *.* to repl@'10.1.1.%' identified by '123';
mysql> grant all privileges on *.* to mha@'10.1.1.40' identified by '123';
mysql> flush privileges;
5. 在slave上设置同步信息(slave1和slave2都要设置)
mysql> change master to master_host='10.1.1.10',master_port=3306,master_user='repl',master_password='123',master_auto_position=1;
mysql> start slave;
Query OK, 0 rows affected (0.02 sec)
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.1.1.10
Master_User: repl
Master_Port: 3307
Connect_Retry: 60
Master_Log_File: master-bin.000001
Read_Master_Log_Pos: 812
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 1024
Relay_Master_Log_File: master-bin.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
6. 测试主从同步
略
5. MHA软件安装
5.1 不同节点安装软件
说明:在所有节点安装 ==mha-node== 软件包,在 ==mha 管理==端再安装 mha-manager 软件包
[root@mgr ~]# yum -y install mha4mysql-manager-0.57-0.el7.noarch.rpm
[root@master ~]# yum –y install mha4mysql-node-0.57-0.el7.noarch.rpm
[root@slave1 ~]# yum -y install mha4mysql-node-0.57-0.el7.noarch.rpm
[root@slave2 ~]# yum –y install mha4mysql-node-0.57-0.el7.noarch.rpm
5.2 配置ssh互信
说明:
- 在生产环境中几乎都是禁止root远程登陆服务器的,所以ssh免密码登陆要在admin用户下进行配置,这是处于安全角度考虑出发。
- admin用户可以是任意普通用户
- 该普通用户用于mha的管理节点远程访问mysql复制组中的所有主机,完成一些其他工作
① 所有机器创建admin用户
# useradd admin
# echo 123|passwd --stdin admin
② 配置mgr主机到其他主机的admin用户互信
mgr端:
[root@mgr ~]# su - admin
[admin@mgr ~]$ ssh-keygen -P "" -f ~/.ssh/id_rsa
[admin@mgr ~]$ cd .ssh/
[admin@mgr .ssh]$ ls
id_rsa id_rsa.pub
[admin@mgr .ssh]$ mv id_rsa.pub authorized_keys
[admin@mgr .ssh]$ for i in 10 20 30;do scp -r ../.ssh/ 10.1.1.$i:~/;done
测试免密登录:
[admin@mgr .ssh]$ ssh 10.1.1.10
[admin@mgr .ssh]$ ssh 10.1.1.20
[admin@mgr .ssh]$ ssh 10.1.1.30
5.3 配置admin用户的sudo权限
- 配置admin用户执行sudo命令权限
[root@master ~]# vim /etc/sudoers.d/admin
#User_Alias 表示具有sudo权限的用户列表; Host_Alias表示主机的列表
User_Alias MYSQL_USERS = admin
#Runas_Alias 表示用户以什么身份登录
Runas_Alias MYSQL_RUNAS = root
#Cmnd_Alias 表示允许执行命令的列表
Cmnd_Alias MYSQL_CMNDS = /sbin/ifconfig,/sbin/arping
MYSQL_USERS ALL = (MYSQL_RUNAS) NOPASSWD: MYSQL_CMNDS
[root@master ~]# for i in 20 30;do scp /etc/sudoers.d/admin 10.1.1.$i:/etc/sudoers.d/; done
- 测试admin用户是否可以挂载VIP
[admin@master ~]$ sudo /sbin/ifconfig ens33:1 10.1.1.100 broadcast 10.1.1.255 netmask 255.255.255.0
[admin@master ~]$ sudo /sbin/arping -f -q -c 5 -w 5 -I ens33 -s 10.1.1.100 -U 10.1.1.5
[admin@master ~]$ ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.1.1.5 netmask 255.255.255.0 broadcast 10.1.1.255
inet6 fe80::20c:29ff:fe4c:a304 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:4c:a3:04 txqueuelen 1000 (Ethernet)
RX packets 87558 bytes 7043682 (6.7 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 981178 bytes 2419766959 (2.2 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ens33:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 10.1.1.100 netmask 255.255.255.0 broadcast 10.1.1.255
ether 00:0c:29:4c:a3:04 txqueuelen 1000 (Ethernet)
补充:
arping:用来向局域网内的其它主机发送ARP请求的指令,可以用来测试局域网内的某个IP是否已被使用。
Usage: arping [-fqbDUAV] [-c count] [-w timeout] [-I device] [-s source] destination
-f:收到第一个响应包后退出。
-q:quite模式,不显示输出。
-c:发送指定的count个ARP REQUEST包后停止。如果指定了-w参数,则会等待相同数量的ARP REPLY包,直到超时为止。
-w:指定一个超时时间,单位为秒,arping在到达指定时间后退出,无论期间发送或接收了多少包。在这种情况下,arping在发送完指定的count(-c)个包后并不会停止,而是等待到超时或发送的count个包都进行了回应后才会退出。
-I:指定设备名,用来发送ARP REQUEST包的网络设备的名称。
-D:重复地址探测模式,用来检测有没有IP地址冲突,如果没有IP冲突则返回0。
-s:设置发送ARP包的IP资源地址
-U:无理由的(强制的)ARP模式去更新别的主机上的ARP CACHE列表中的本机的信息,不需要响应。
-h:显示帮助页。
5.4 创建mha相关配置文件
- 创建 相关的工作目录
[root@mgr ~]# mkdir /etc/mha/
[root@mgr ~]# mkdir -p /data/mha/masterha/app1
[root@mgr ~]# chown -R admin. /data/mha
- 创建mha局部配置文件
[root@mgr ~]# cat /etc/mha/app1.conf
[server default]
# 设置监控用户和密码
user=mha
password=123
# 设置复制环境中的复制用户和密码
repl_user=repl
repl_password=123
# 设置ssh的登录用户名
ssh_user=admin
# 设置监控主库,发送ping包的时间间隔,默认是 3 秒,尝试三次没有回应的时候自动进行failover
ping_interval=3
# 设置mgr的工作目录
manager_workdir=/data/mha/masterha/app1
# 设置mysql master 保存 binlog 的目录,以便 MHA 可以找到 master 的二进制日志
master_binlog_dir=/usr/local/mysql/data
# 设置 master 的 pid 文件
master_pid_file=/usr/local/mysql/data/master.itcast.cn.pid
# 设置 mysql master 在发生切换时保存 binlog 的目录(在mysql master上创建这个目录)
remote_workdir=/data/mysql/mha
# 设置 mgr 日志文件
manager_log=/data/mha/masterha/app1/app1-3306.log
# MHA 到 master 的监控之间出现问题,MHA Manager 将会尝试从slave1和slave2登录到master上
secondary_check_script=/usr/bin/masterha_secondary_check -s 10.1.1.20 -s 10.1.1.30 --user=admin --port=22 --master_host=10.1.1.10 --master_port=3306
# 设置自动 failover 时候的切换脚本
master_ip_failover_script="/etc/mha/master_ip_failover.sh 10.1.1.100 1"
# 设置手动切换时候的切换脚本
#master_ip_online_change_script="/etc/mha/master_ip_online_change.sh 10.1.1.100 1"
# 设置故障发生后关闭故障主机脚本
# shutdown_script="/etc/mha/power_manager"
[server1]
hostname=10.1.1.10
port= 3306
candidate_master=1
[server2]
hostname=10.1.1.20
port= 3306
candidate_master=1
[server3]
hostname=10.1.1.30
port= 3306
no_master=1
5.5 上传相应脚本
[root@mgr ~]# ls /etc/mha/
app1.conf master_ip_failover.sh master_ip_online_change.sh power_manager
注意:脚本内容中要修改网卡名字和连接用户为admin
my $vip = shift;
my $interface = 'ens33'; 网卡名
my $key = shift;
...
sub stop_vip() {
my $ssh_user = "admin"; 用户名
print "=======$ssh_stop_vip==================\n";
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
[root@mgr ~]# chmod +x /etc/mha/master_ip_*
6. 检查ssh互信和集群状态
- 检查ssh互信
[admin@mgr ~]$ masterha_check_ssh --conf=/etc/mha/app1.conf
Mon Jan 28 02:11:40 2019 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Mon Jan 28 02:11:40 2019 - [info] Reading application default configuration from /etc/mha/app1.conf..
Mon Jan 28 02:11:40 2019 - [info] Reading server configuration from /etc/mha/app1.conf..
Mon Jan 28 02:11:40 2019 - [info] Starting SSH connection tests..
Mon Jan 28 02:11:42 2019 - [debug]
Mon Jan 28 02:11:40 2019 - [debug] Connecting via SSH from admin@10.1.1.20(10.1.1.20:22) to admin@10.1.1.10(10.1.1.10:22)..
Mon Jan 28 02:11:41 2019 - [debug] ok.
Mon Jan 28 02:11:41 2019 - [debug] Connecting via SSH from admin@10.1.1.20(10.1.1.20:22) to admin@10.1.1.30(10.1.1.30:22)..
Mon Jan 28 02:11:42 2019 - [debug] ok.
Mon Jan 28 02:11:42 2019 - [debug]
Mon Jan 28 02:11:41 2019 - [debug] Connecting via SSH from admin@10.1.1.30(10.1.1.30:22) to admin@10.1.1.10(10.1.1.10:22)..
Mon Jan 28 02:11:41 2019 - [debug] ok.
Mon Jan 28 02:11:41 2019 - [debug] Connecting via SSH from admin@10.1.1.30(10.1.1.30:22) to admin@10.1.1.20(10.1.1.20:22)..
Mon Jan 28 02:11:41 2019 - [debug] ok.
Mon Jan 28 02:11:42 2019 - [debug]
Mon Jan 28 02:11:40 2019 - [debug] Connecting via SSH from admin@10.1.1.10(10.1.1.10:22) to admin@10.1.1.20(10.1.1.20:22)..
Mon Jan 28 02:11:41 2019 - [debug] ok.
Mon Jan 28 02:11:41 2019 - [debug] Connecting via SSH from admin@10.1.1.10(10.1.1.10:22) to admin@10.1.1.30(10.1.1.30:22)..
Mon Jan 28 02:11:41 2019 - [debug] ok.
Mon Jan 28 02:11:42 2019 - [info] All SSH connection tests passed successfully.
以上信息说明ok
- 检查集群状态
[admin@mgr ~]$ masterha_check_repl --conf=/etc/mha/app1.conf
Mon Jan 28 02:12:52 2019 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Mon Jan 28 02:12:52 2019 - [info] Reading application default configuration from /etc/mha/app1.conf..
Mon Jan 28 02:12:52 2019 - [info] Reading server configuration from /etc/mha/app1.conf..
Mon Jan 28 02:12:52 2019 - [info] MHA::MasterMonitor version 0.57.
Mon Jan 28 02:12:53 2019 - [info] GTID failover mode = 1
Mon Jan 28 02:12:53 2019 - [info] Dead Servers:
Mon Jan 28 02:12:53 2019 - [info] Alive Servers:
Mon Jan 28 02:12:53 2019 - [info] 10.1.1.10(10.1.1.10:3307)
Mon Jan 28 02:12:53 2019 - [info] 10.1.1.20(10.1.1.20:3306)
Mon Jan 28 02:12:53 2019 - [info] 10.1.1.30(10.1.1.30:3306)
Mon Jan 28 02:12:53 2019 - [info] Alive Slaves:
Mon Jan 28 02:12:53 2019 - [info] 10.1.1.20(10.1.1.20:3306) Version=5.6.35-log (oldest major version between slaves) log-bin:enabled
Mon Jan 28 02:12:53 2019 - [info] GTID ON
Mon Jan 28 02:12:53 2019 - [info] Replicating from 10.1.1.10(10.1.1.10:3307)
Mon Jan 28 02:12:53 2019 - [info] Primary candidate for the new Master (candidate_master is set)
Mon Jan 28 02:12:53 2019 - [info] 10.1.1.30(10.1.1.30:3306) Version=5.6.35-log (oldest major version between slaves) log-bin:enabled
Mon Jan 28 02:12:53 2019 - [info] GTID ON
Mon Jan 28 02:12:53 2019 - [info] Replicating from 10.1.1.10(10.1.1.10:3307)
Mon Jan 28 02:12:53 2019 - [info] Primary candidate for the new Master (candidate_master is set)
Mon Jan 28 02:12:53 2019 - [info] Current Alive Master: 10.1.1.10(10.1.1.10:3307)
Mon Jan 28 02:12:53 2019 - [info] Checking slave configurations..
Mon Jan 28 02:12:53 2019 - [info] read_only=1 is not set on slave 10.1.1.20(10.1.1.20:3306).
Mon Jan 28 02:12:53 2019 - [info] read_only=1 is not set on slave 10.1.1.30(10.1.1.30:3306).
Mon Jan 28 02:12:53 2019 - [info] Checking replication filtering settings..
Mon Jan 28 02:12:53 2019 - [info] binlog_do_db= , binlog_ignore_db=
Mon Jan 28 02:12:53 2019 - [info] Replication filtering check ok.
Mon Jan 28 02:12:53 2019 - [info] GTID (with auto-pos) is supported. Skipping all SSH and Node package checking.
Mon Jan 28 02:12:53 2019 - [info] Checking SSH publickey authentication settings on the current master..
Mon Jan 28 02:12:53 2019 - [info] HealthCheck: SSH to 10.1.1.10 is reachable.
Mon Jan 28 02:12:53 2019 - [info]
10.1.1.10(10.1.1.10:3307) (current master)
+--10.1.1.20(10.1.1.20:3306)
+--10.1.1.30(10.1.1.30:3306)
Mon Jan 28 02:12:53 2019 - [info] Checking replication health on 10.1.1.20..
Mon Jan 28 02:12:53 2019 - [info] ok.
Mon Jan 28 02:12:53 2019 - [info] Checking replication health on 10.1.1.30..
Mon Jan 28 02:12:53 2019 - [info] ok.
Mon Jan 28 02:12:53 2019 - [info] Checking master_ip_failover_script status:
Mon Jan 28 02:12:53 2019 - [info] /etc/mha/master_ip_failover.sh 10.1.1.100 1 --command=status --ssh_user=admin --orig_master_host=10.1.1.10 --orig_master_ip=10.1.1.10 --orig_master_port=3307
Checking the Status of the script.. OK
Mon Jan 28 02:12:53 2019 - [info] OK.
Mon Jan 28 02:12:53 2019 - [warning] shutdown_script is not defined.
Mon Jan 28 02:12:53 2019 - [info] Got exit code 0 (Not master dead).
MySQL Replication Health is OK.
以上信息说明ok
7. 检查MHA-Mgr状态
[admin@mgr ~]$ masterha_check_status --conf=/etc/mha/app1.conf
app1 is stopped(2:NOT_RUNNING).
开启MHA Manager监控:
[admin@mgr ~]$ nohup masterha_manager --conf=/etc/mha/app1.conf --remove_dead_master_conf --ignore_last_failover &
再次查看监控状态:
[admin@mgr ~]$ masterha_check_status --conf=/etc/mha/app1.conf
app1 (pid:16338) is running(0:PING_OK), master:10.1.1.10
注意:
1. 如果正常,会显示”PING_OK ”,否则会显示”NOT_RUNNING ”,说明 MHA监控没有开启
2. 使用admin用户启动监控,否则会报权限拒绝
3. 手动停止监控命令:masterha_stop --conf=/etc/mha/app1.conf
二、自动Failover测试
1. 安装测试工具
[root@master ~]# yum -y install sysbench
2. 创建测试数据
mysql> create database autotest charset utf8;
Query OK, 1 row affected (0.17 sec)
mysql> grant all on *.* to 'mha'@'localhost' identified by '123';
Query OK, 0 rows affected (0.14 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.11 sec)
mysql> exit
Bye
[root@master ~]# sysbench /usr/share/sysbench/oltp_read_only.lua \
--mysql-host=10.1.1.33 --mysql-port=3306 --mysql-user=mha \
--mysql-password=123 --mysql-socket=/tmp/mysql.sock \
--mysql-db=autotest --db-driver=mysql --tables=1 \
--table-size=100000 --report-interval=10 --threads=128 --time=120 prepare
3. 模拟故障
[root@master ~]# service mysql stop
Shutting down MySQL............ [ OK ]
4. 查看切换过程
[root@mgr ~]# tail -f /data/mha/masterha/app1/app1-3306.log
....
----- Failover Report -----
----- Failover Report -----
app1: MySQL Master failover 10.1.1.10(10.1.1.10:3306) to 10.1.1.20(10.1.1.20:3306) succeeded
Master 10.1.1.10(10.1.1.10:3307) is down!
Check MHA Manager logs at mgr.itcast.cn:/data/mha/masterha/app1/app1-3306.log for details.
Started automated(non-interactive) failover.
Invalidated master IP address on 10.1.1.10(10.1.1.10:3307)
Selected 10.1.1.20(10.1.1.20:3306) as a new master.
10.1.1.20(10.1.1.20:3306): OK: Applying all logs succeeded.
10.1.1.20(10.1.1.20:3306): OK: Activated master IP address.
10.1.1.30(10.1.1.30:3306): OK: Slave started, replicating from 10.1.1.20(10.1.1.20:3306)
10.1.1.20(10.1.1.20:3306): Resetting slave info succeeded.
Master failover to 10.1.1.20(10.1.1.20:3306) completed successfully.
Master failover to 10.1.1.6(10.1.1.6:3307) completed successfully.
三、常见错误
1. 管理节点配置文件错误
[root@mgr ~]# cat /etc/mha/app1.conf
[server default]
# 设置监控用户和密码,该用户是master上创建的数据库管理账号,拥有所有权限
user=mha
password=123
# 设置复制环境中的复制用户和密码,注意需要有以下权限:
#REPLICATION SLAVE和REPLICATION CLIENT
repl_user=repl
repl_password=123
# 设置ssh的登录用户名
ssh_user=admin
....
[server1]
hostname=10.1.1.10
port= 3307
candidate_master=1
[server2]
hostname=10.1.1.20
port= 3306
candidate_master=1
[server3]
hostname=10.1.1.30
port= 3306
no_master=1
注意:一定要配置正确的IP和端口号
2. 复制用户权限密码错误
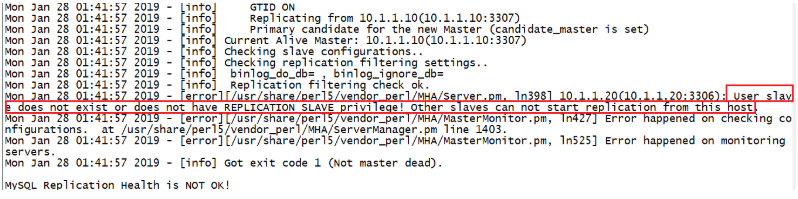
原因:复制用户slave没有相关权限,REPLICATION SLAVE和==REPLICATION CLIENT==
3. 其他错误
MHA集群至少需要2个slave,所以如果只有一台slave的话,检查也是通不过的!
